The Approximate Counting Algorithm
This might seem like a straightforward question, but how high can you count on your fingers? This depends on how many fingers you have, but in general the answer has to be 10, right?
Well, not exactly, it can actually go much, much higher with a few simple abstractions.
The first strategy is to think of your fingers as binary registers, like so [1]:

If your fingers are out, they count as a 1 for that register. If they are not, they count as a 0. This means that after you have decided on the appropriate finger configuration, you have created a bitstring that can be read from left to right, where each number represents a power of 2. For this example, we would have a bitstring of 1110010101, which reads to 917:
Because you have 10 fingers and each one represents a power of 2, you can count up to a maximum of or 1023, which is about 100 times higher than simple finger counting! For those who might be wondering why you can count to instead of exactly, remember that each finger represents a power of 2. The right thumb counts as and the left thumb is . With all fingers out, we have counted to .
So what if we wanted to go beyond 1023? Well, we could start counting with our fingers as trits where 0 is closed, 1 is half-up, and 2 is fully up. There are actually a huge variety of different ways we could move our hands about to count in odd ways, but we are interested in a more concrete problem: how high can we count with only 10 bits?
This is almost exactly the problem that Morris encountered in Bell Labs around 1977 [2]. There, he was given an 8-bit register and asked to count much higher than . His solution was to invent a new method known as the approximate counting algorithm. With this method, he could count to about with a relatively low error (standard deviation, ). Using 10 registers (fingers), he could count to about with similar parameters, which is undoubtedly impressive!
The approximate counting algorithm is an early predecessor to streaming algorithms where information must be roughly processed in real-time. As we dive into those methods later, this chapter will certainly be updated. For now, we will not be showing any proofs (though those might come later as well), but a rigorous mathematical description of this method can be found in a follow-up paper by Philippe Flajolet [3]. In addition, there are several blogs and resources online that cover the method to varying degrees of accessibility [4] [5].
Here, we hope to provide a basic understanding of the method, along with code implementations for anyone who might want to try something similar in the future.
A Simple Example
If we need to count more than 255 items with 8 bits, there is one somewhat simple strategy: count every other item. This means that we will increment our counter with 2, 4, 6, 8... items, effectively doubling the number of items we can count to 511! (Note: that "!" is out of excitement and is not a factorial.) Similarly, if we need to count above 511, we can increment our counter every 3 or 4 items; however, the obvious drawback to this method is that if we only count every other item, there is no way to represent odd numbers. Similarly, if we count every 3rd or 4th item, we would miss out on any numbers that are not multiples of our increment number.
The most important thing to take away from this line of reasoning is that counting can be done somewhat approximately by splitting the process into two distinct actions: incrementing the counter and storing the count, itself. For example, every time a sheep walks by, you could lift a finger. In this case, the act of seeing a sheep is a trigger for incrementing your counter, which is stored on your hand. As mentioned, you could also lift a finger every time 2 or 3 sheep go by to count higher on your hand. In code, bits are obviously preferred to hands for long-term storage.
Taking this example a bit further, imagine counting 1,000,000 sheep. If we wanted to save all of them on 8 bits (maximum size of 255), we could increment our counter every sheep. By counting in this way, we would first need to count around 4000 sheep before incrementing the main counter by 1. After all the sheep have gone by, we would have counted up to 250 on our counter, and also counted up to on a separate counter 250 times. This has a few important consequences:
- If the final number of sheep is not a multiple of 4000, then we will have an error associated with the total count of up to 4000 (0.4%).
- There is no way to determine the final number of sheep if it is not a multiple of 4000.
- We now need some way to count up to 4000 before incrementing the main counter. This means we need a second counter!
In a sense, 4000 would be a type of "counting resolution" for our system. Overall, a 0.4% error is not bad, but it is possible to ensure that the approximate count is more accurate (but potentially less precise) by using randomness to our advantage.
That is to say, instead of incrementing out counter every 4000th sheep, we could instead give each item a chance of incrementing our main counter. This averages out to be roughly 1 count every 4000 sheep, but the expectation value of a large number of counting experiments should be the correct number. This means that even though we need to count all the sheep multiple times to get the right expectation value, we no longer need to keep a separate counter for the counting resolution of 4000.
Because multiple counting trials are necessary to ensure the correct result, each counting experiment will have some associated error (sometimes much higher than 0.4%). To quantify this error, let's actually perform multiple the experiment, as shown below:
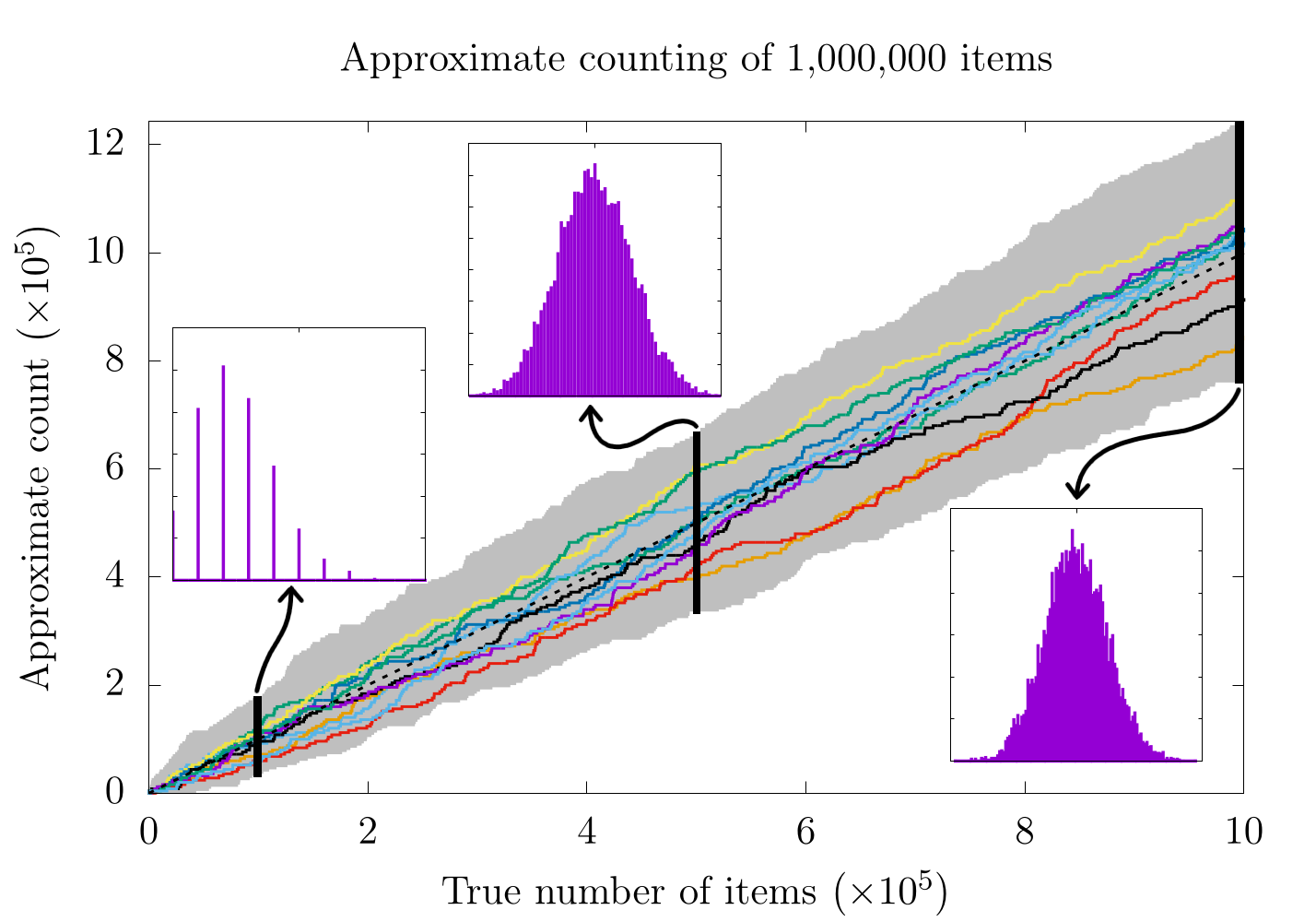
In this image, we have counted 1,000,000 sheep (items) 10,000 different times. In each run, we have given each item a 0.025% chance to flip our primary counter and have given each increment in our primary counter a weight of 4000 items. We have plotted 10 of the 10,000 runs (chosen at random), and each upward tick of the lines represents one of the items winning a game of chance and adding 1 to the primary counter and thus adding 4000 to the approximate count. We have also shaded the maximum and minimum approximate count for each true count of the 10,000 trials in gray, thereby highlighting the range of possible outputs. On top of the plot, we have shown the distribution of all 10,000 runs for the approximate count at 10,000, 500,000, and 1,000,000 items.
There's a lot to unpack here, so let's start with the upward trending lines. Here, it seems like the approximate counts are roughly following the line of (dotted black line), which would indicate simple counting (without any randomness or approximation). This makes sense because in a perfect world, the approximate count would always be exactly equal to the true number of items being counted. Unfortunately, none of the lines shown here exactly follow . In fact, it would be impossible for any of the approximations to do so because we are always increasing the approximation in steps of 4000 while the true count increments by 1 with each new item. That said, the average of all these counts together is a really good approximation for the true number of items.
This is where the 3 additional plots come in:
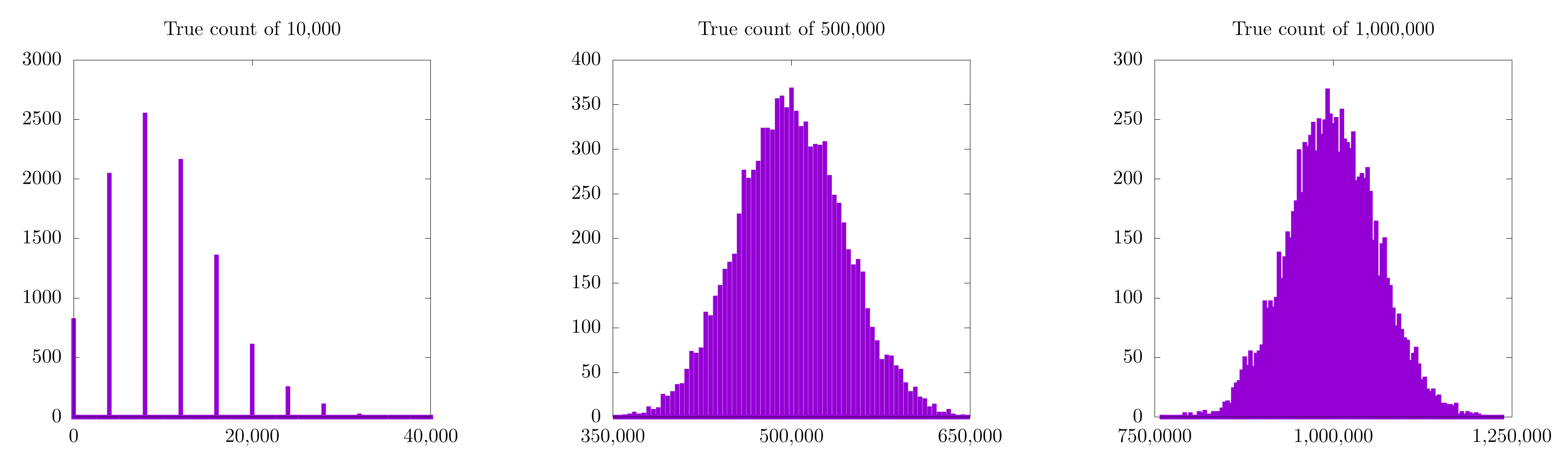
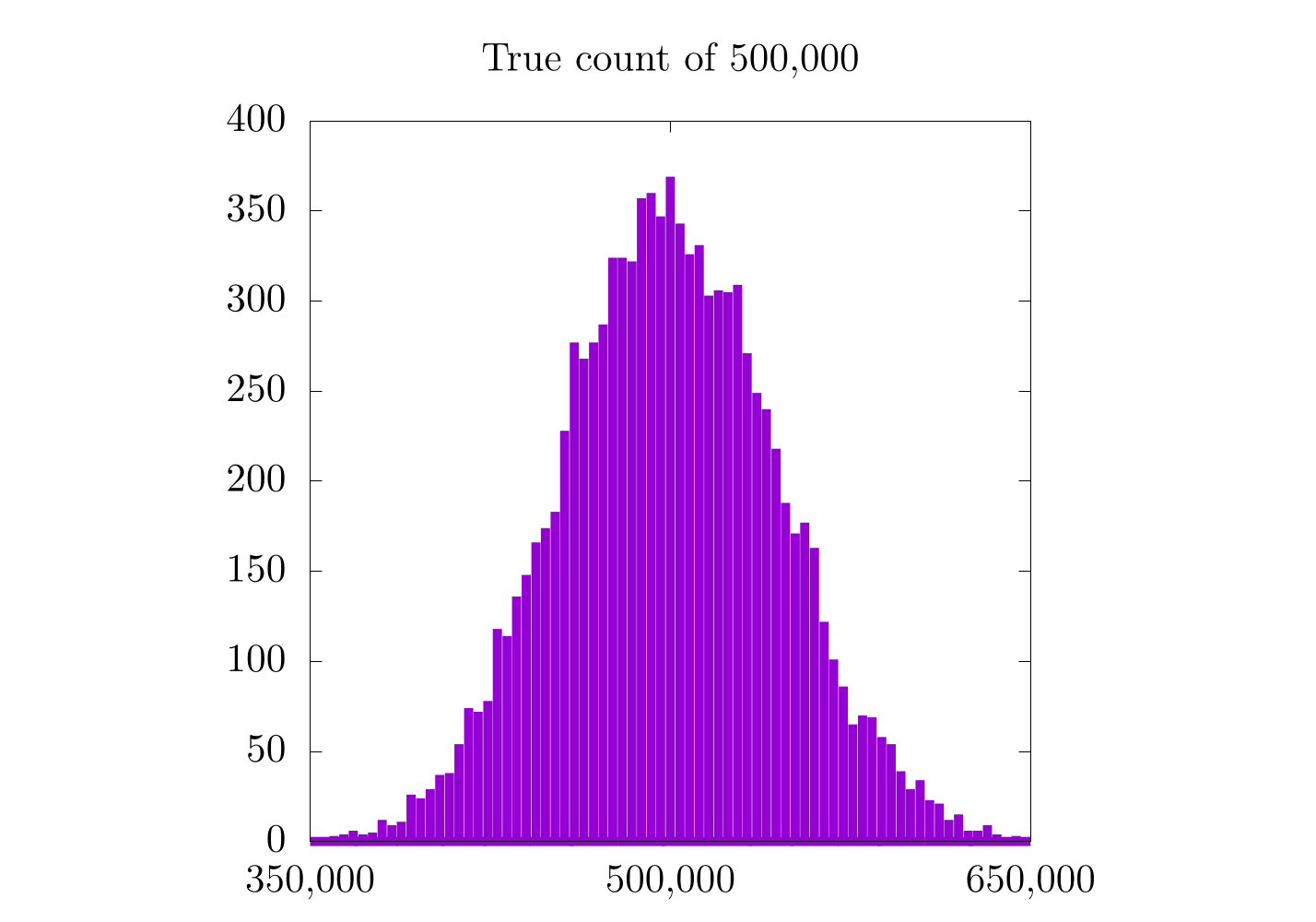
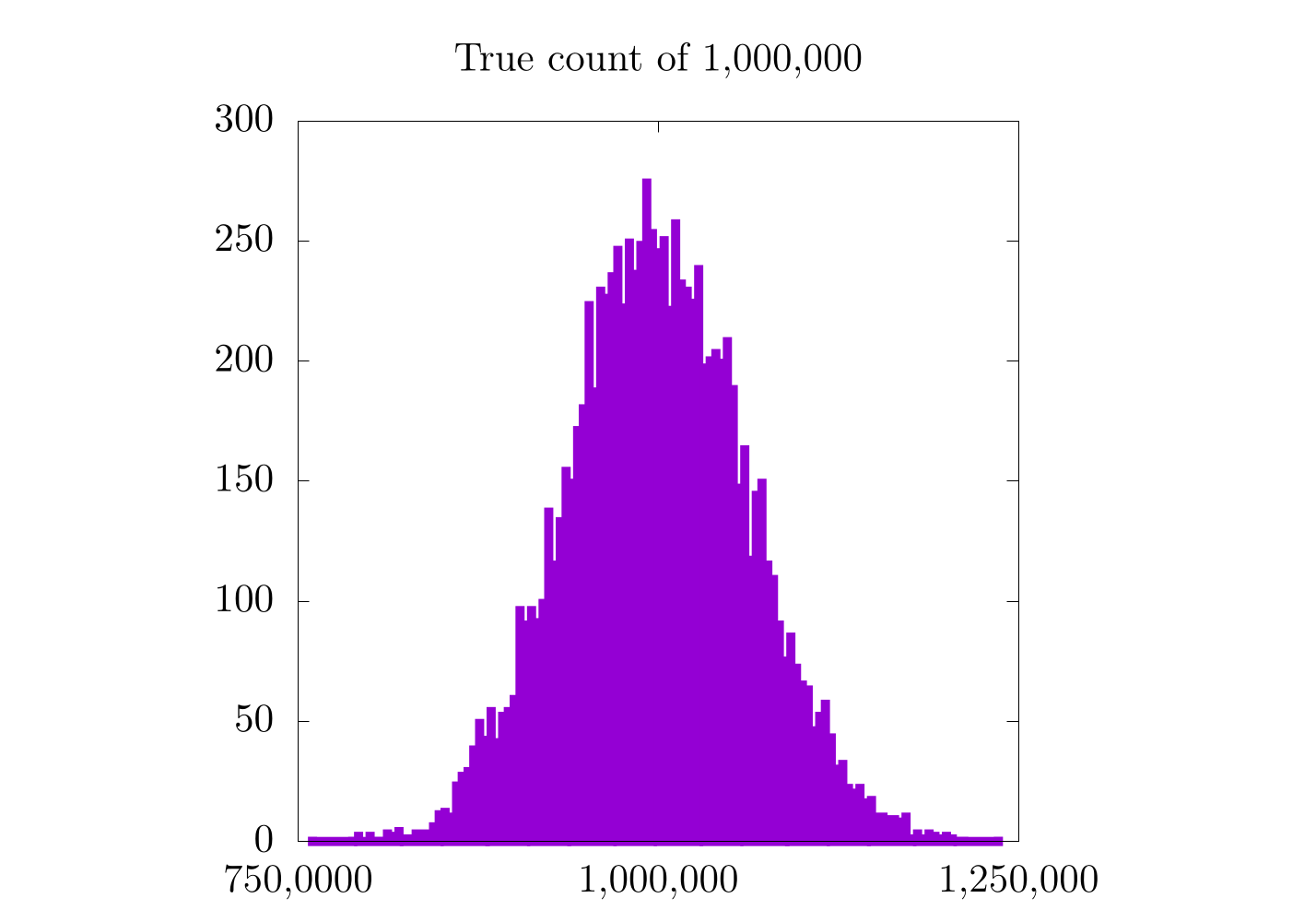
Each of these is a histogram of the approximate count for all 10,000 runs at 10,000 (left), 500,000 (middle), and 1,000,000 (left) items. All three (especially the approximation for 1,000,000) look Gaussian, and the peak of the Gaussian seems to be the correct count. In fact, the expectation value for our approximate counting scheme will always be correct. In practice, this means that we can approximate any count on a small number of bits by doing a large number of counting trials and averaging their results.
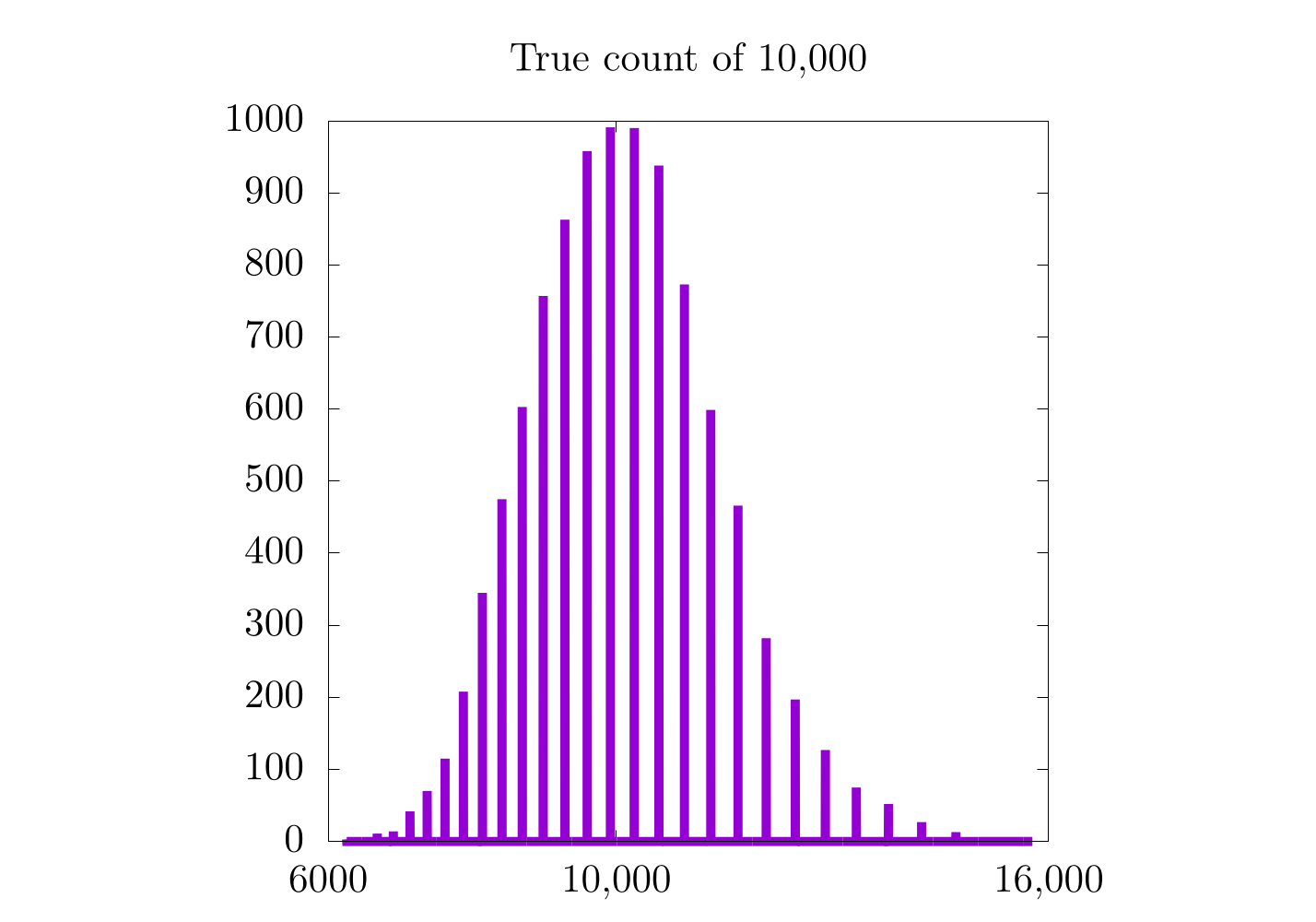
There is still a little catch that becomes more evident as we look at the approximation for 10,000 items. In this case, even though the expectation value for the Gaussian distribution looks correct, it's kinda hard to tell exactly because there are only 8 (or so) possible values for each individual experiment. Essentially, we are trying to count to 10,000 in steps of 4,000. Clearly the closest we can get on any individual run is either 8,000 or 12,000, as these are multiples of 4,000. Simply put: we cannot resolve 10,000 items with this method!
Does this mean that this counting method is less useful for a small number of items? In a sense, yes. Here is a table for the true count, approximate count, and percent error for 10,000, 500,000, and 1,000,000 for the case where we do 10,000 counting experiments:
| True Count | Approximate Count | Percent Error |
|---|---|---|
| 10,000 | 9,958.0 | 0.42 |
| 500,000 | 499,813.2 | 0.037 |
| 1,000,000 | 999,466.0 | 0.053 |
Here, it seems that the percent error is 10 times higher when we count 10,000 items; however, with these numbers, I could imagine some people reading this are thinking that we are splitting hairs. A 0.42% error is still really good, right? Right. It's definitely not bad, but this was with 10,000 counting experiments. Here a new table where we only did 10:
| True Count | Approximate Count | Percent Error |
|---|---|---|
| 10,000 | 8,000.0 | 20.0 |
| 500,000 | 483,200.0 | 3.36 |
| 1,000,000 | 961,600.0 | 3.84 |
This time, there is a 20% error when counting to 10,000. That's unacceptably high!
To solve this problem, we need to find some way to for the value of each increment on the actual counter to be more meaningful for lower counts. This is precisely the job for a logarithm, which is what we will be looking at in the next section. For now, it's important to look at another anomaly: why are the percent errors for the 500,000 and 1,000,000 cases so close?
I gotta be honest, I don't know the correct answer here, but I would guess that it has something to do with the fact that both 500,000 and 1,000,000 are multiples of 4000 so our counting scheme can resolve both of them with roughly equal precision. On top of that, both values are significantly higher than 4,000 so the counting resolution does not have as significant of an impact on the measured count. Simply put, 4000 is a big step size when counting to 10,000, but a smaller one when counting to 500,000 or 1,000,000.
As an important note, each approximate count shown in the tables above was the expectation value for a Gaussian probability distribution of different counting experiments all providing a guess at what the count could be. Because we are no longer counting with integer increments but instead with probability distributions, we now need to quantify our error with the tools of probability, namely standard deviations.
In the next section, we will tackle both issues brought up here:
- In order to better approximate different scales of counting, it makes sense to use a logarithmic scale.
- Because we are counting by using the expectation value of a Gaussian probability distribution from a set of counting experiments, it makes sense to quantify error with the tools we learned from probability and statistics.
So I guess we should hop to it!
Adding a logarithm
At this stage, I feel it's important to use terminology that more closely matches Morris's original paper [2], so we will begin to talk about events, which are a general abstraction to the previous item / sheep analogy. We will also introduce three different values:
- : the number of events that have occurred.
- : the number we have stored in our bitstring.
- : the approximate number of events that have occurred.
It's important to stop here and think about what's actually going on. We have a certain number of events () that have occurred and have stored that number on a binary register as . Traditionally, the number stored on the binary register would be exactly equal to the number of events, but because we do not have enough space on the register, we end up settling for an approximation of the number of events, . This is precisely what we did in the previous example, where and .
As mentioned, using a constant scaling value (4000) for our approximate counting scheme means that the approximation is not ideal for a smaller number of events. For this reason, it might be more appropriate to create a new method of storing the number of events by using a logarithmic scale, such that
which would mean that the approximate count would be
In this case, we are adding 1 to the argument of the logarithm for because and we start counting at 1; therefore, we need some way to represent the value of 0. Also, for this we can use any base logarithm (like ), but because we are dealing with bits, it makes sense to use base 2. We'll talk about different bases next. To be clear, here is a table of several values that could be stored in a bitstring along with their corresponding approximate counts:
| 0 | |
This means that we can hold from to with 8 bits using this new method.
So let's now think about what happens every time a new event occurs. To do this, Morris calculated a new value:
where is the approximate count for the next possible value stored in the register. In this case, will always be between 0 and 1, so we can consider it to be the probability of whether we should increment our stored count or not. For example, if we have a stored value of 2 (), then
This indicates that there will be a 25% chance to increment from 2 to 3. In practice, this means that we need to create another random variable and set our counter such that
Again, is essentially the probability that we will increment our counter with each object, and as we count higher, the probability decreases exponentially.
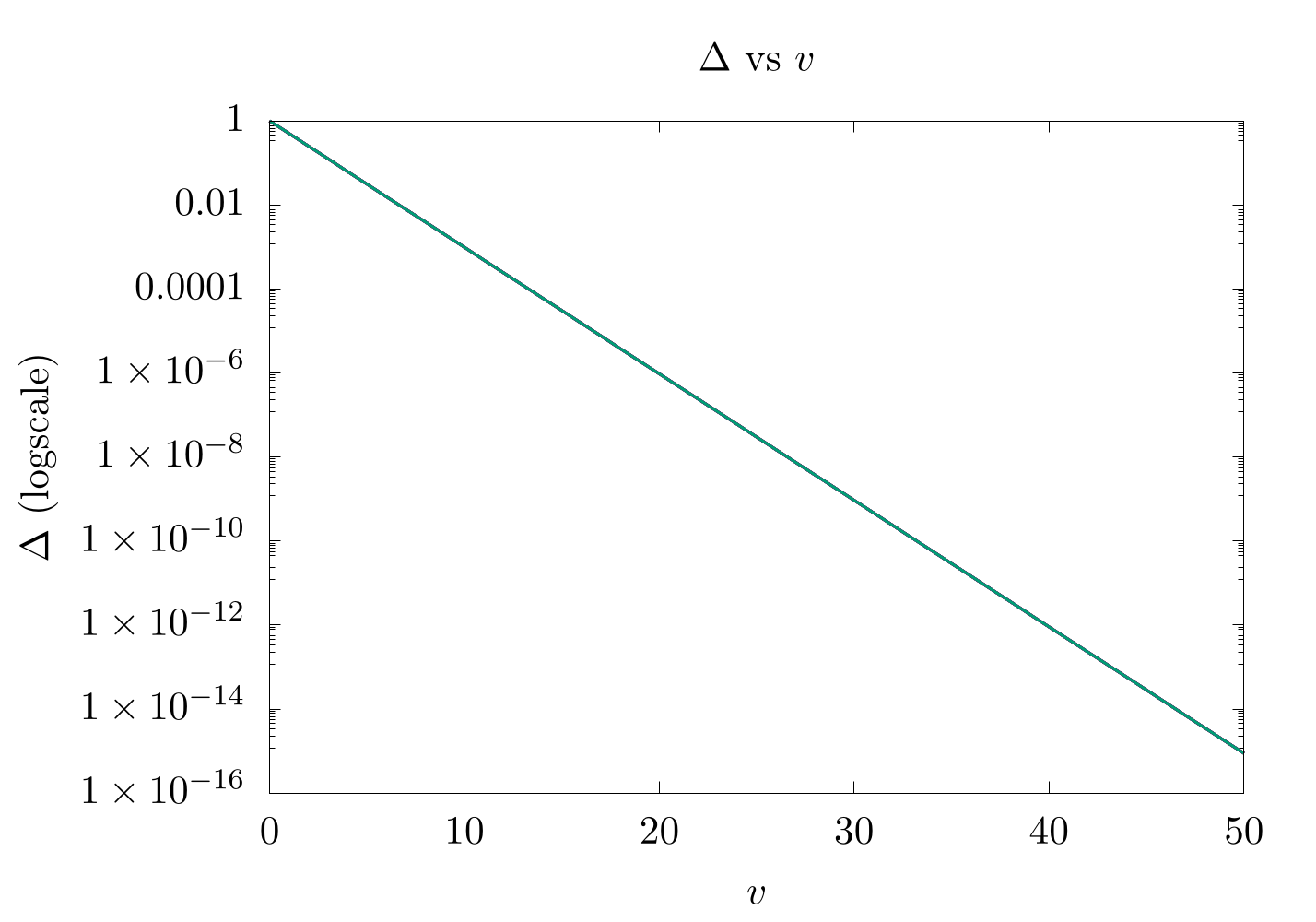
Note: the -axis to this figure is in logscale, which is why it looks like a straight line.
Before leaving this section, it's important to note that the highest anyone can count with this method in base 2 using an 8-bit register is . That's great! Way, way better than 255, but we can still go higher with a different base of logarithm. For example, if we use as our base, we can get up to . In addition, by choosing smaller bases, we can also find a more accurate approximate count for lower values. In practice, we want to select a base that allows us to count to a value of the same order (or one order higher) than the number of events we are expected to have.
In the next section, we will consider how to generalize this logarithmic method to take arbitrary bases into account.
A slightly more general logarithm
Let's start by considering the differences between base and base . For base ,
If we were to update our count and wanted to keep the value in the counter as accurate as possible, then the new value in the register with every new event would be
This is generally not an integer value, but must be an integer value (unless we want to try and store floating-point values (which we definitely don't have space for)), so what do we do in this situation?
Well, let's look at the very first event where we need to increment our count from 0 to 1. With base , there would only be a 58% chance of counting the first event (), and if the event is counted, the value in the register would be . Again, the expectation value for a bunch of trials is correct, but we did not have this issue with base 2, because
when . As a reminder, the above formula is a way to convert any logarithm from a given base (in this case ) to another base (in this case 2).
Going one step further, we need to chose a specific base to a logarithm that will at least ensure that the first count is correct, and for this reason, Morris studied a specific solution:
Here, is an effective tuning parameter and sets the maximum count allowed by the bitstring and the expected error. The expression acts as a base for the logarithm and exponents and ensures that the first count of will also set the value . As an example, if the bitstring can be a maximum of 255 (for 8 bits) and we arbitrarily set , then the highest possible count with this approach will be , which was the number reported in Morris's paper. If we perform a few counting experiments, we find that this formula more closely tracks smaller numbers than before (when we were not using the logarithm):
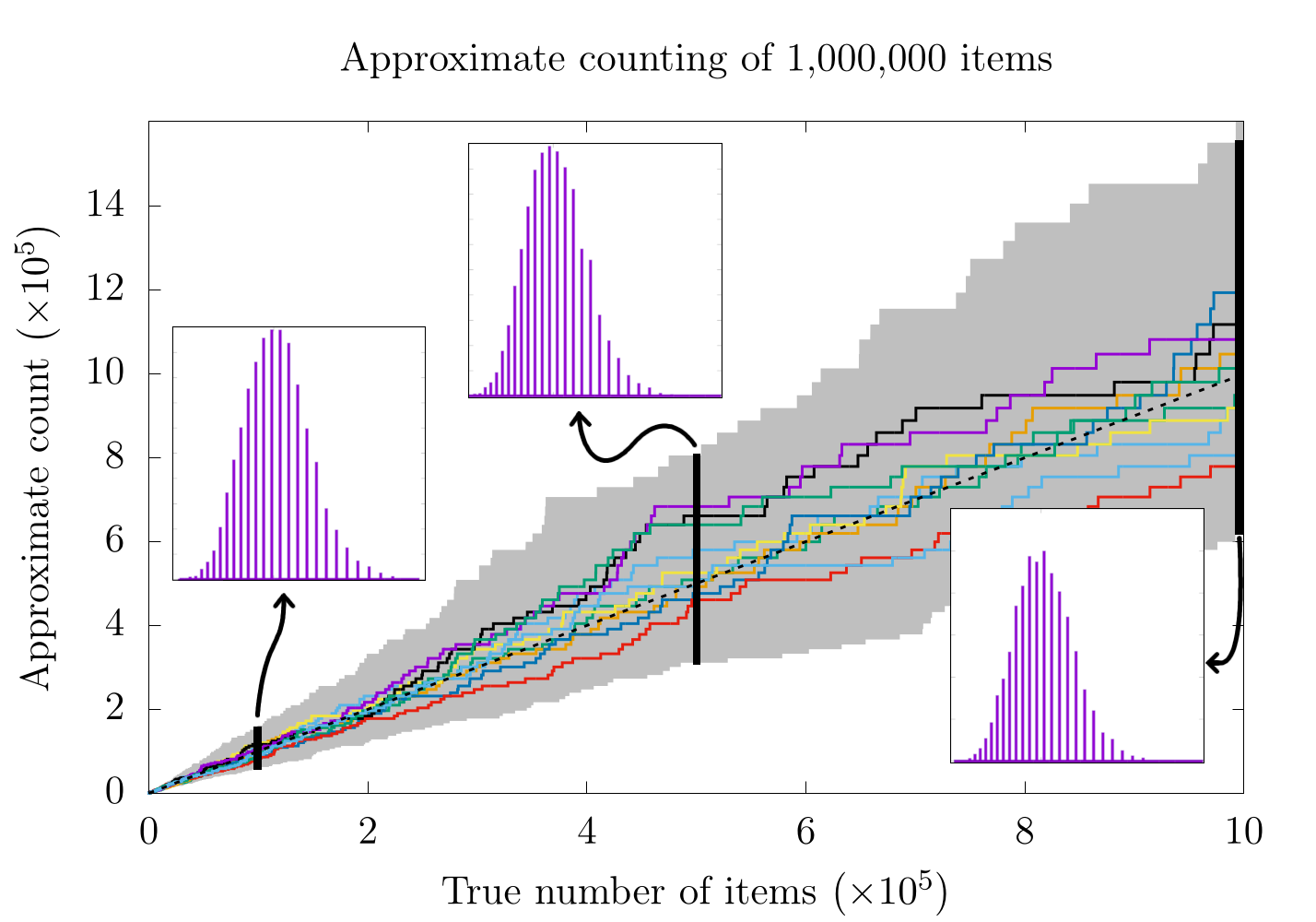
Now, let's pause for a second and look back at the case where our counting resolution was a constant 4000:
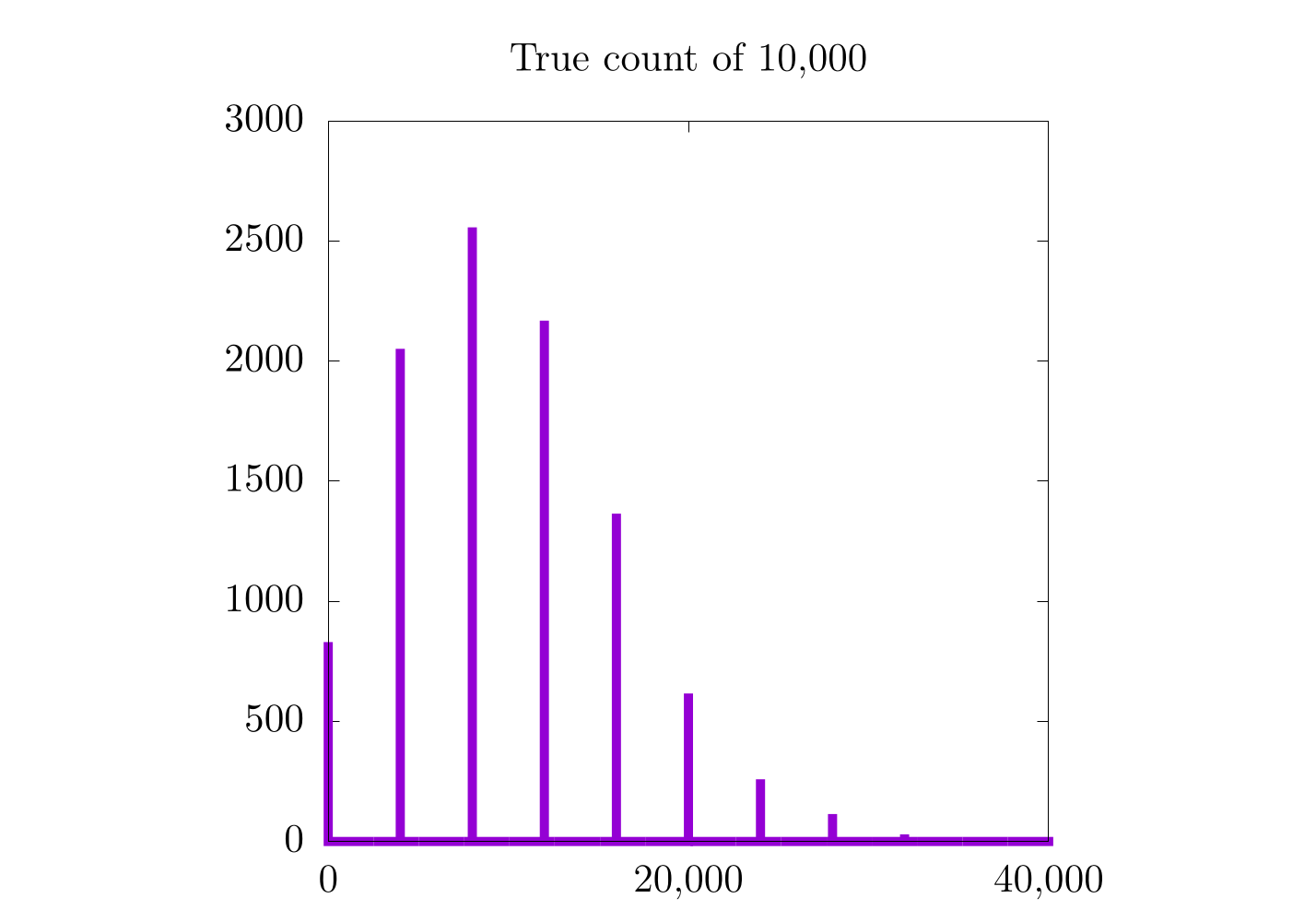
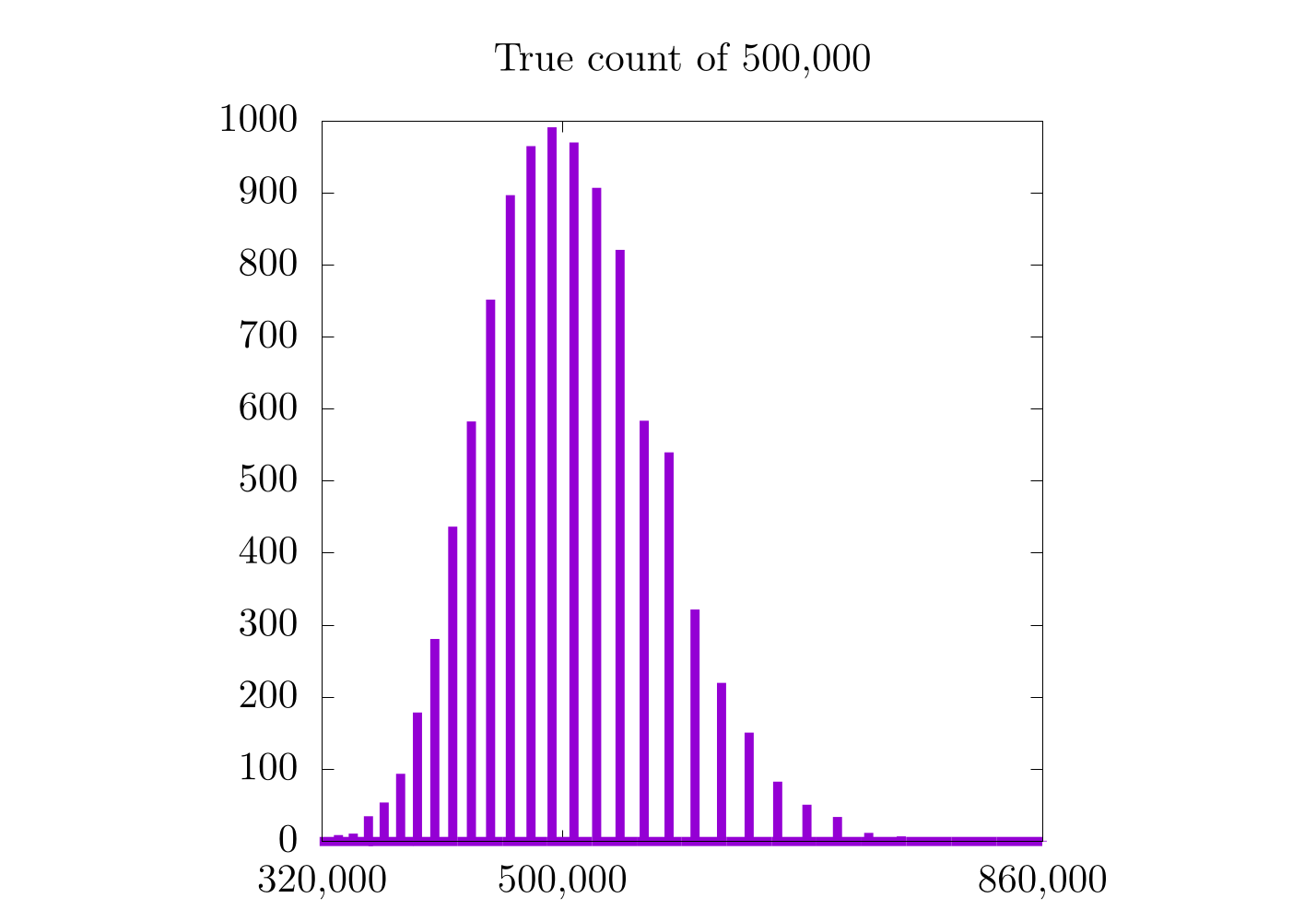
It would seem that for higher counts, the previous method (with a constant counting resolution) is actually better! Remember that in the case of a constant counting resolution, the step size is really small for higher counts, so we get a higher resolution probability distribution for when we count 500,000 and 1,000,000 items. With the logarithmic scale, this is not the case, as the counting resolution now changes with the count, itself. This is also why all three probability distributions for the logarithmic scaling have a similar distance between each bar. In fact, it is probably worthwhile to look at each case more specifically:
| Constant Counting Resolution | Logarithmic Counting Resolution |
|---|---|
 |
 |
 |
 |
 |
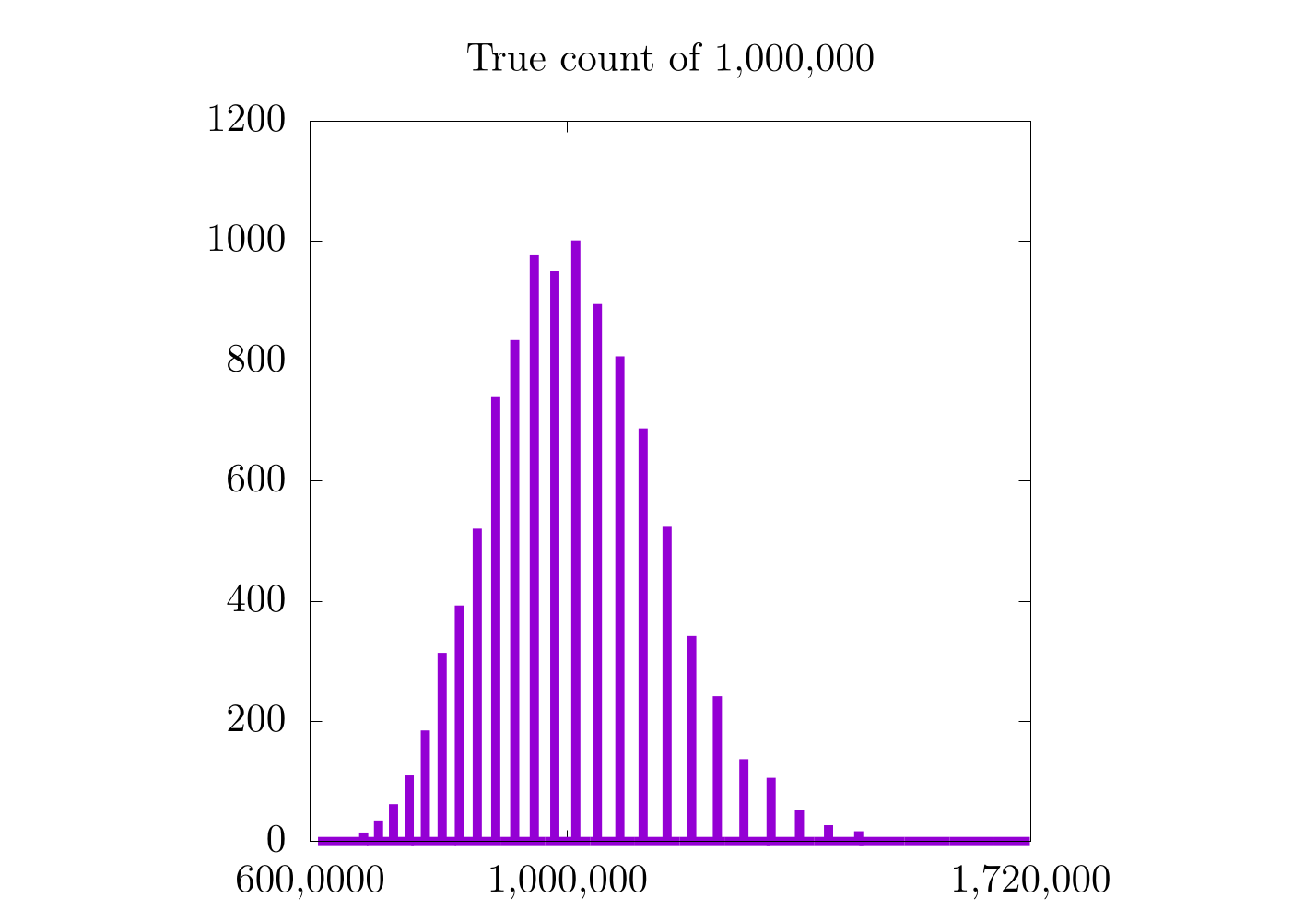 |
In the case where we count only to 10,000, we see a moderate increase in the resolution of the probability distribution, but in the 500,000 and 1,000,000 cases, we do not. It's also important to notice that the logarithmic plots are a bit skewed to the left and are only Gaussian on logarithmic scales along . On the one hand, the logarithmic plots are nice in that they have the same relative error for all scales, but on the other hand, the error is relatively high.
How do we fix this? Well, by modifying the base of the logarithm with the variable :
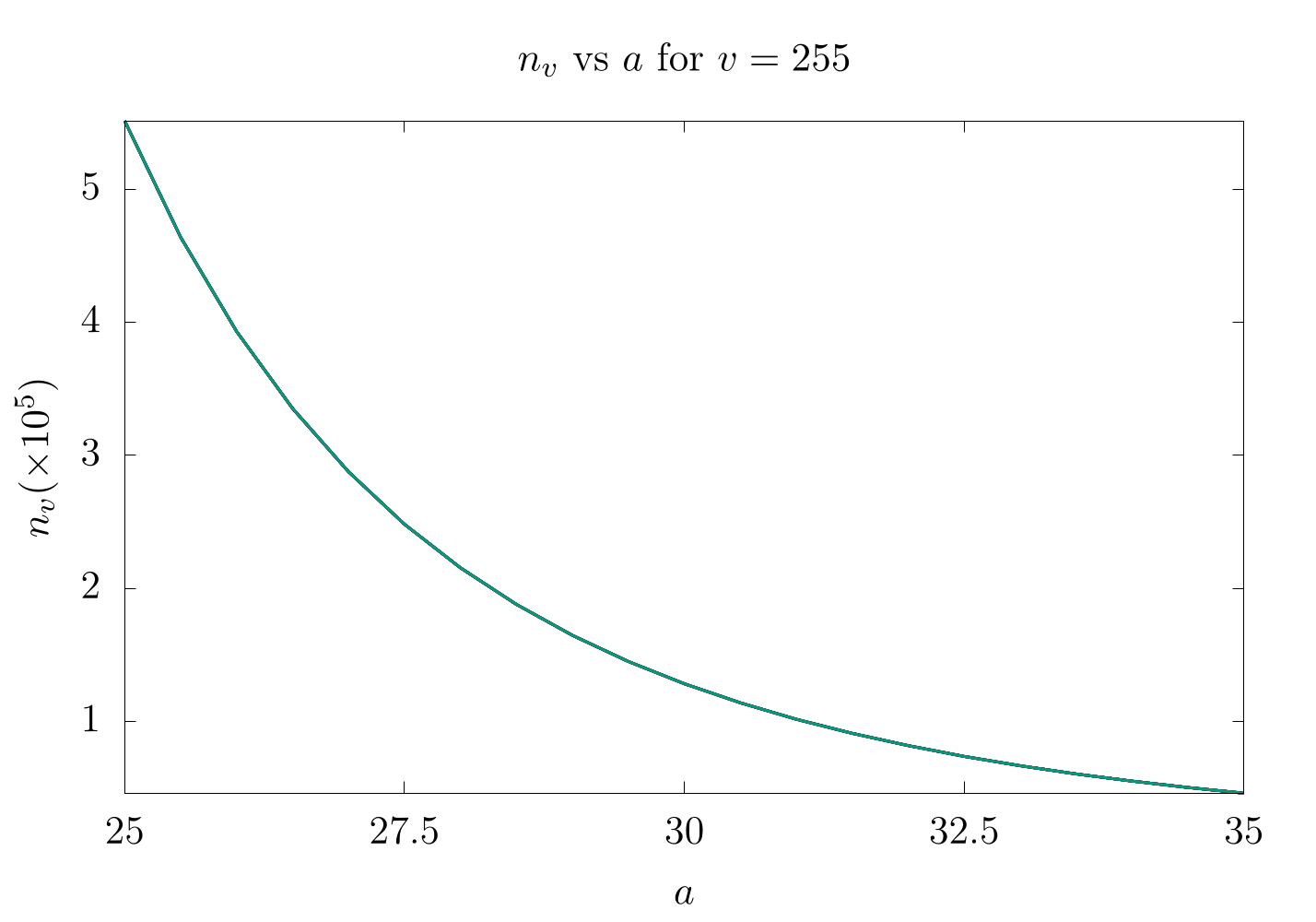
Here, we show the differences in for when . It is important to twiddle based on what the maximum count is expected for each experiment. As an important note, the expected error estimate (variance) for each count will be
Finally, before ending the paper, Morris mentioned that it is possible to pre-compute all values for all where is the largest value possible integer with that bitstring (as an example, 255 for 8 bits). This was probably more useful in 1978 than it is now, but it's still nice to keep in mind if you find yourself working on a machine with compute constrictions.
Video Explanation
Here is a video describing the Approximate Counting Algorithm:
Example Code
For this example, we have returned to the question asked above: how high can someone count on their fingers using the approximate counting algorithm? We know from the formula that with and 10 bits, we should be able to count to , but what happens when we perform the actual experiment?
As we do not have any objects to count, we will instead simulate the counting with a while loop that keeps going until out bitstring is 1023 ().
using Test
# This function takes
# - v: value in register
# - a: a scaling value for the logarithm based on Morris's paper
# It returns n(v,a), the approximate count
function n(v, a)
a*((1+1/a)^v-1)
end
# This function takes
# - v: value in register
# - a: a scaling value for the logarithm based on Morris's paper
# It returns a new value for v
function increment(v, a)
# delta is the probability of incrementing our counter
delta = 1/(n(v+1, a)-n(v, a))
if rand() <= delta
return v + 1
else
return v
end
end
# This simulates counting and takes
# - n_items: number of items to count and loop over
# - a: a scaling value for the logarithm based on Morris's paper
# It returns n(v,a), the approximate count
function approximate_count(n_items, a)
v = 0
for i = 1:n_items
v = increment(v, a)
end
return n(v, a)
end
# This function takes
# - n_trials: the number of counting trials
# - n_items: the number of items to count to
# - a: a scaling value for the logarithm based on Morris's paper
# - threshold: the maximum percent error allowed
# It returns a true / false test value
function test_approximate_count(n_trials, n_items, a, threshold)
samples = [approximate_count(n_items, a) for i = 1:n_trials]
avg = sum(samples)/n_trials
if (abs((avg - n_items) / n_items) < threshold)
println("passed")
else
println("failed")
end
end
println("[#]\nCounting Tests, 100 trials")
println("[#]\ntesting 1,000, a = 30, 10% error")
test_approximate_count(100, 1000, 30, 0.1)
println("[#]\ntesting 12,345, a = 10, 10% error")
test_approximate_count(100, 12345, 10, 0.1)
# Note: with a lower a, we need more trials, so a higher % error here.
println("[#]\ntesting 222,222, a = 0.5, 20% error")
test_approximate_count(100, 222222, 0.5, 0.2)
#include <assert.h>
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// This function returns a pseudo-random number between 0 and 1
double drand()
{
return (double)rand() / RAND_MAX;
}
// This function takes
// - v: value in register
// - a: a scaling value for the logarithm based on Morris's paper
// It returns the approximate count
double n(double v, double a)
{
return a * (pow(1 + 1 / a, v) - 1);
}
// This function takes
// - v: value in register
// - a: a scaling value for the logarithm based on Morris's paper
// It returns a new value for v
double increment(double v, double a)
{
// delta is the probability of incrementing our counter
double delta = 1 / (n(v + 1, a) - n(v, a));
if (drand() <= delta) {
return v + 1;
}
return v;
}
// This function simulates counting and takes
// - n_items: number of items to count and loop over
// - a: a scaling value for the logarithm based on Morris's paper
// It returns n(v, a), the approximate count
double approximate_count(size_t n_items, double a)
{
double v = 0;
for (size_t i = 0; i < n_items; ++i) {
v = increment(v, a);
}
return n(v, a);
}
// This function takes
// - n_trials: the number of counting trials
// - n_items: the number off items to count
// - a: a scaling value for the logarithm based on Morris's paper
// - threshold: the maximum percent error allowed
// It terminates the program on failure
void test_approximation_count(size_t n_trials, size_t n_items, double a,
double threshold)
{
double sum = 0.0;
for (size_t i = 0; i < n_trials; ++i) {
sum += approximate_count(n_items, a);
}
double avg = sum / (double)n_trials;
double items = (double)n_items;
if (fabs((avg - items) / items) < threshold){
printf("passed\n");
}
else{
printf("failed\n");
}
}
int main()
{
srand((unsigned int)time(NULL));
printf("[#]\nCounting Tests, 100 trials\n");
printf("[#]\ntesting 1,000, a = 30, 10%% error\n");
test_approximation_count(100, 1000, 30, 0.1);
printf("[#]\ntesting 12,345, a = 10, 10%% error\n");
test_approximation_count(100, 12345, 10, 0.1);
printf("[#]\ntesting 222,222, a = 0.5, 20%% error\n");
test_approximation_count(100, 222222, 0.5, 0.2);
return 0;
}
#include <cmath>
#include <iostream>
#include <numeric>
#include <random>
// Returns a pseudo-random number generator
std::default_random_engine& rng() {
// Initialize static pseudo-random engine with non-deterministic random seed
static std::default_random_engine randEngine(std::random_device{}());
return randEngine;
}
// Returns a random double in [0, 1)
double drand() {
return std::uniform_real_distribution<double>(0.0, 1.0)(rng());
}
// This function takes
// - v: value in register
// - a: a scaling value for the logarithm based on Morris's paper
// It returns n(v,a), the approximate count
auto n(double v, double a) { return a * (pow((1 + 1 / a), v) - 1); }
// This function takes
// - v: value in register
// - a: a scaling value for the logarithm based on Morris's paper
// It returns a new value for v
auto increment(int v, double a) {
// delta is the probability of incrementing our counter
const auto delta = 1 / (n(v + 1, a) - n(v, a));
return (drand() <= delta) ? v + 1 : v;
}
// This simulates counting and takes
// - n_items: number of items to count and loop over
// - a: a scaling value for the logarithm based on Morris's paper
// It returns n(v,a), the approximate count
auto approximate_count(int n_items, double a) {
auto v = 0;
for (auto i = 0; i < n_items; ++i)
v = increment(v, a);
return n(v, a);
}
// This function takes
// - n_trials: the number of counting trials
// - n_items: the number of items to count to
// - a: a scaling value for the logarithm based on Morris's paper
// - threshold: the maximum percent error allowed
// It returns a "pass" / "fail" test value
auto test_approximate_count(
int n_trials, int n_items, double a, double threshold) {
auto sum = 0.0;
for (auto i = 0; i < n_trials; ++i)
sum += approximate_count(n_items, a);
const auto avg = sum / n_trials;
return std::abs((avg - n_items) / n_items) < threshold ? "passed" : "failed";
}
int main() {
std::cout << "[#]\nCounting Tests, 100 trials\n";
std::cout << "[#]\ntesting 1,000, a = 30, 10% error \n"
<< test_approximate_count(100, 1000, 30, 0.1) << "\n";
std::cout << "[#]\ntesting 12,345, a = 10, 10% error \n"
<< test_approximate_count(100, 12345, 10, 0.1) << "\n";
// Note : with a lower a, we need more trials, so a higher % error here.
std::cout << "[#]\ntesting 222,222, a = 0.5, 20% error \n"
<< test_approximate_count(100, 222222, 0.5, 0.2) << "\n";
}
from random import random
# This function takes
# - v: value in register
# - a: a scaling value for the logarithm based on Morris's paper
# It returns n(v,a), the approximate_count
def n(v, a):
return a*((1 + 1/a)**v - 1)
# This function takes
# - v: value in register
# - a: a scaling value for the logarithm based on Morris's paper
# It returns a new value for v
def increment(v, a):
delta = 1/(n(v + 1, a) - n(v, a))
if random() <= delta:
return v + 1
else:
return v
#This simulates counting and takes
# - n_items: number of items to count and loop over
# - a: a scaling value for the logarithm based on Morris's paper
# It returns n(v,a), the approximate count
def approximate_count(n_items, a):
v = 0
for i in range(1, n_items + 1):
v = increment(v, a)
return n(v, a)
# This function takes
# - n_trials: the number of counting trials
# - n_items: the number of items to count to
# - a: a scaling value for the logarithm based on Morris's paper
# - threshold: the maximum percent error allowed
# It returns a true / false test value
def test_approximate_count(n_trials, n_items, a, threshold):
samples = [approximate_count(n_items, a) for i in range(1, n_trials + 1)]
avg = sum(samples)/n_trials
if abs((avg - n_items)/n_items) < threshold:
print("passed")
else:
print("failed")
print("[#]\nCounting Tests, 100 trials")
print("[#]\ntesting 1,000, a = 30, 10% error")
test_approximate_count(100, 1000, 30, 0.1)
print("[#]\ntesting 12,345, a = 10, 10% error")
test_approximate_count(100, 12345, 10, 0.1)
print("[#]\ntesting 222,222, a = 0.5, 20% error")
test_approximate_count(100, 222222, 0.5, 0.2)
// This function takes
// - v: value in register
// - a: a scaling value for the logarithm based on Morris's paper
// It returns n(v,a), the approximate count
fn n(v: f64, a: f64) -> f64 {
a * ((1_f64 + 1_f64 / a).powf(v) - 1_f64)
}
// This function takes
// - v: value in register
// - a: a scaling value for the logarithm based on Morris's paper
// It returns a new value for v
fn increment(v: f64, a: f64) -> f64 {
// delta is the probability of incrementing our counter
let delta = 1_f64 / (n(v + 1_f64, a) - n(v, a));
if rand::random::<f64>() <= delta {
v + 1_f64
} else {
v
}
}
// This simulates counting and takes
// - n_items: number of items to count and loop over
// - a: a scaling value for the logarithm based on Morris's paper
// It returns n(v,a), the approximate count
fn approximate_count(n_items: usize, a: f64) -> f64 {
let mut v = 0_f64;
for _ in 0..n_items {
v = increment(v, a);
}
v
}
// This function takes
// - n_trials: the number of counting trials
// - n_items: the number of items to count to
// - a: a scaling value for the logarithm based on Morris's paper
// - threshold: the maximum percent error allowed
// It returns a "passed" / "failed" test value
fn test_approximate_count(n_trials: usize, n_items: usize, a: f64, threshold: f64) {
let avg = std::iter::from_fn(|| Some(approximate_count(n_items, a)))
.take(n_trials)
.sum::<f64>() / n_trials as f64;
let n_items_float = n_items as f64;
if ((avg - n_items_float) / n_items_float) < threshold {
println!("passed");
} else {
println!("failed");
}
}
fn main() {
println!("testing 1,000, a = 30, 10% error");
test_approximate_count(100, 1000, 30_f64, 0.1);
println!("testing 12,345, a = 10, 10% error");
test_approximate_count(100, 12345, 10_f64, 0.1);
println!("testing 222,222, a = 0.5, 20% error");
test_approximate_count(100, 222222, 0.5, 0.2);
}
import java.lang.Math;
import java.util.stream.DoubleStream;
public class ApproximateCounting {
/*
* This function taks
* - v: value in register
* - a: a scaling value for the logarithm based on Morris's paper
* It returns the approximate count
*/
static double n(double v, double a) {
return a * (Math.pow(1 + 1 / a, v) - 1);
}
/*
* This function takes
* - v: value in register
* - a: a scaling value for the logarithm based on Morris's paper
* It returns the new value for v
*/
static double increment(double v, double a) {
double delta = 1 / (n(v + 1, a) - n(v, a));
if (Math.random() <= delta) {
return v + 1;
} else {
return v;
}
}
/*
* This function takes
* - v: value in register
* - a: a scaling value for the logarithm based on Morris's paper
* It returns the new value for v
*/
static double approximateCount(int nItems, double a) {
double v = 0;
for (int i = 0; i < nItems; i++) {
v = increment(v, a);
}
return n(v, a);
}
/*
* This function takes
* - nTrials: the number of counting trails
* - nItems: the number of items to count
* - a: a scaling value for the logarithm based on Morris's paper
* - threshold: the maximum percent error allowed
* It terminates the program on failure
*/
static void testApproximateCount(int nTrials, int nItems, double a, double threshold) {
double avg = DoubleStream.generate(() -> approximateCount(nItems, a))
.limit(nTrials)
.average()
.getAsDouble();
if (Math.abs((avg - nItems) / nItems) < threshold) {
System.out.println("passed");
} else {
System.out.println("failed");
}
}
public static void main(String args[]) {
System.out.println("[#]\nCounting Tests, 100 trials");
System.out.println("[#]\ntesting 1,000, a = 30, 10% error");
testApproximateCount(100, 1_000, 30, 0.1);
System.out.println("[#]\ntesting 12,345, a = 10, 10% error");
testApproximateCount(100, 12_345, 10, 0.1);
System.out.println("[#]\ntesting 222,222, a = 0.5, 20% error");
testApproximateCount(100, 222_222, 0.5, 0.2);
}
}
Bibliography
License
Code Examples
The code examples are licensed under the MIT license (found in LICENSE.md).
Text
The text of this chapter was written by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
![]()
Images/Graphics
- The image "Finger Counting" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Approximate trials" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Histograms" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Delta v v" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Approximate trials Logarithm" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Histograms 10,000" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Histograms exp 10,000" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Histograms 500,000" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Histograms exp 500,000" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Histograms 1,000,000" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "Histograms exp 1,000,000" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
- The image "A from 25 to 35" was created by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.