Just how costly is rejection sampling anyway?
Let's imagine we want to have a final Gaussian distribution with particles in it. With the Cartesian Box—Muller method, this is easy: start the initial distribution(s) with particles and then do the transform. Things can be just as easy with the Polar Box—Muller method as well, so long as we start with a uniformly distributed circle instead of a uniformly distributed square. That is to say, so long as we do the rejection sampling before-hand, the Polar Box—Muller method will always be more efficient. To be fair, there are methods to generate a uniform distribution of points within a circle without rejection sampling, but let's assume that we require rejection sampling for this example
This means that someone somehow needs to do the rejection sampling for the Polar method, which is sometimes a painful process. This also means that the Box—Muller method can be used to teach some of the fundamentals of General-Purpose GPU computing. Note that because of the specificity of this problem, all the code in this subsection will be in Julia and using the package KernelAbstractions.jl, which allows us to execute the same kernels on either CPU or GPU hardware depending on how we configure things.
Let's first consider the case where we do the rejection sampling as a part of the polar Box—Muller kernel instead of as a pre-processing step. In this case, we can imagine 2 separate ways of writing our kernel:
- With replacement: In this case, we absolutely require the final number of points in our Gaussian distribution to be , so if we find a point outside of the unit circle while running the kernel, we will "re-roll" again for a new point that is within the circle.
- Without replacement: This means that we will start with a uniform distribution of points, but end with a Gaussian of points. In this case, if we find a point outside of the unit circle while running the kernel, we just ignore it by setting the output values to NaNs (or something similar).
OK, so first with replacement:
@kernel function polar_muller_replacement!(input_pts, output_pts, sigma, mu)
tid = @index(Global, Linear)
@inbounds r_0 = input_pts[tid, 1]^2 + input_pts[tid, 2]^2
while r_0 > 1 || r_0 == 0
p1 = rand()*2-1
p2 = rand()*2-1
r_0 = p1^2 + p2^2
end
@inbounds output_pts[tid,1] = sigma * input_pts[tid,1] *
sqrt(-2 * log(r_0) / r_0) + mu
@inbounds output_pts[tid,2] = sigma * input_pts[tid, 2] *
sqrt(-2 * log(r_0) / r_0) + mu
end
This is an awful idea for a number of reasons. Here are a few:
- If we find a point outside of the unit circle, we have to continually look for new points until we do find one inside of the circle. Because we are running this program in parallel, where each thread transforms one point at a time, some threads might take literally forever to find a new point (if we are really unlucky).
- To generate new points, we need to re-generate a uniform distribution, but what if our uniform distribution is not random? What if it's a grid (or something similar) instead? In this case, we really shouldn't look for a new point on the inside of the circle as all those points have already been accounted for.
- The
rand()function is kinda tricky on some parallel platforms (like GPUs) and might not work out of the box. In fact, the implementation shown above can only be run on the CPU.
OK, fine.
I don't think anyone expected a kernel with a while loop inside of it to be fast.
So what about a method without replacement?
Surely there is no problem if we just ignore the while loop altogether!
Well, the problem with this approach is a bit less straightforward, but first, code:
@kernel function polar_muller_noreplacement!(input_pts, output_pts, sigma, mu)
tid = @index(Global, Linear)
@inbounds r_0 = input_pts[tid, 1]^2 + input_pts[tid, 2]^2
# this method is only valid for points within the unit circle
if r_0 == 0 || r_0 > 1
@inbounds output_pts[tid,1] = NaN
@inbounds output_pts[tid,2] = NaN
else
@inbounds output_pts[tid,1] = sigma * input_pts[tid,1] *
sqrt(-2 * log(r_0) / r_0) + mu
@inbounds output_pts[tid,2] = sigma * input_pts[tid, 2] *
sqrt(-2 * log(r_0) / r_0) + mu
end
end
To start discussing why a polar kernel without replacement is also a bad idea, let's go back to the Monte Carlo chapter, where we calculated the value of by embedding it into a circle. There, we found that the probability of a randomly chosen point falling within the unit circle to be , shown in the visual below:

This means that a uniform distribution of points within a circle will reject of points on the square. This also means that if we have a specific value we want for the final distribution, we will need more input values on average!
No problem! In this hypothetical case, we don't need exactly points, so we can just start the initial distributions with points, right?
Right. That will work well on parallel CPU hardware, but on the GPU this will still have an issue.
On the GPU, computation is all done in parallel, but there is a minimum unit of parallelism called a warp. The warp is the smallest number of threads that can execute something in parallel and is usually about 32. This means that if an operation is queued, all 32 threads will do it at the same time. If 16 threads need to execute something and the other 16 threads need to execute something else, this will lead to warp divergence where 2 actions need to be performed instead of 1:
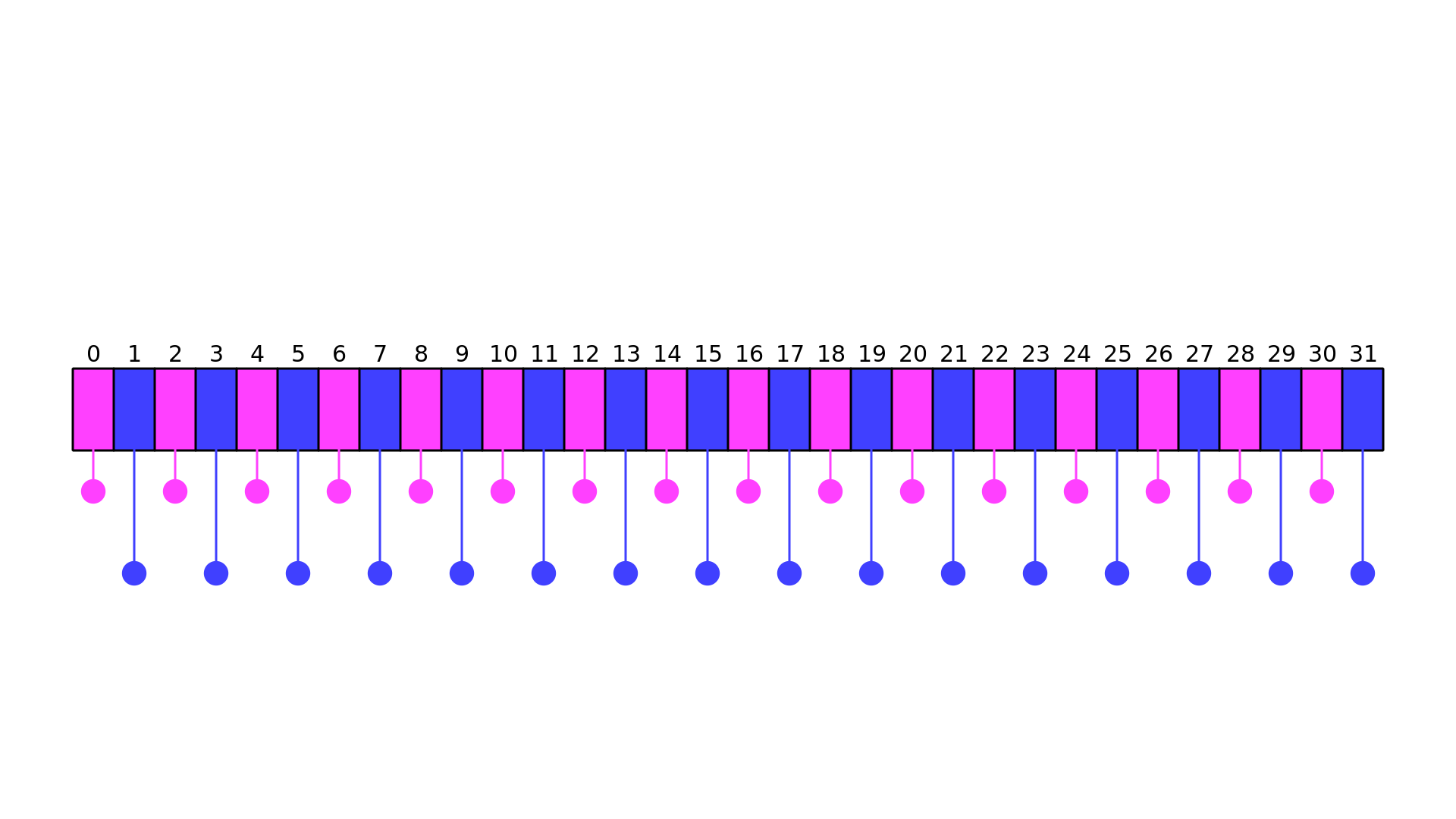
In this image, every odd thread needs to perform the pink action, while the even threads need to perform the blue action.
This means that 2 separate parallel tasks will be performed, one for the even threads, another for the odd threads.
This means that if separate operations are queued, it could take as long for all the threads to do their work!
This is why if statements in a kernel can be dangerous!
If used improperly, they can cause certain threads in a warp to do different things!
So let's imagine that the above image is part of a larger array of values, such that there are a bunch of warps with the same divergence issue. In this case, we could sort the array before-hand so that all even elements come before all odd elements. This would mean that the warps will almost certainly not diverge because the elements queued will all be of the same type and require the same operations. Unfortunately, this comes at the cost of a sorting operation which is prohibitively expensive.
If we look at the above kernel, we are essentially asking of our threads to do something different than everyone else, and because we are usually inputting a uniform random distribution, this means that most warps will have to queue up 2 parallel actions instead of 1.
Essentially, we need to pick our poison:
- Slow and operations with the Cartesian method
- Warp divergence with the Polar method
The only way to know which is better is to perform benchmarks, which we will show in a bit, but there is one final scenario we should consider: what about doing the rejection sampling as a pre-processing step? This would mean that we pre-initialize the polar kernel with a uniform distribution of points in the unit circle. This means no warp divergence, so we can get the best of both worlds, right?
Well, not exactly. The polar Box—Muller method will definitely be faster, but again: someone somewhere needed to do rejection sampling and if we include that step into the process, things become complicated again. The truth is that this pre-processing step is difficult to get right, so it might require a chapter in it's own right.
In many cases, it's worth spending a little time before-hand to make sure subsequent operations are fast, but in this case, we only have a single operation, not a set of operations. The Box—Muller method will usually only be used once at the start of the simulation, which means that the pre-processing step of rejection sampling might end up being overkill.
No matter the case, benchmarks will show the true nature of what we are dealing with here:
| Method | CPU | GPU |
|---|---|---|
| Cartesian | ms | ms |
| Polar without replacement | ms | ms |
| Polar with replacement | ms | NA |
These were run with an Nvidia GTX 970 GPU and a Ryzen 3700X 16 core CPU.
For those interested, the code can be found below.
For these benchmarks, we used Julia's inbuilt benchmarking suite from BenchmarkTools, making sure to sync the GPU kernels with CUDA.@sync.
We also ran with input points.
Here, we see an interesting divergence in the results. On the CPU, the polar method is always faster, but on the GPU, both methods are comparable. I believe this is the most important lesson to be learned from the Box—Muller method: sometimes, no matter how hard you try to optimize your code, different hardware can provide radically different results! It's incredibly important to benchmark code to make sure it is actually is as performant as you think it is!
Full Script
using KernelAbstractions
using CUDA
if has_cuda_gpu()
using CUDAKernels
end
function create_grid(n, endpoints; AT = Array)
grid_extents = endpoints[2] - endpoints[1]
# number of points along any given axis
# For 2D, we take the sqrt(n) and then round up
axis_num = ceil(Int, sqrt(n))
# we are now rounding n up to the nearest square if it was not already one
if sqrt(n) != axis_num
n = axis_num^2
end
# Distance between each point
dx = grid_extents / (axis_num)
# This is warning in the case that we do not have a square number
if sqrt(n) != axis_num
println("Cannot evenly divide ", n, " into 2 dimensions!")
end
# Initializing the array, particles along the column, dimensions along rows
a = AT(zeros(n, 2))
# This works by firxt generating an N dimensional tuple with the number
# of particles to be places along each dimension ((10,10) for 2D and n=100)
# Then we generate the list of all CartesianIndices and cast that onto a
# grid by multiplying by dx and subtracting grid_extents/2
for i = 1:axis_num
for j = 1:axis_num
a[(i - 1) * axis_num + j, 1] = i * dx + endpoints[1]
a[(i - 1) * axis_num + j, 2] = j * dx + endpoints[1]
end
end
return a
end
function create_rand_dist(n, endpoints; AT = Array)
grid_extents = endpoints[2] - endpoints[1]
return(AT(rand(n,2)) * grid_extents .+ endpoints[1])
end
# This function reads in a pair of input points and performs the Cartesian
# Box--Muller transform
@kernel function polar_muller_noreplacement!(input_pts, output_pts, sigma, mu)
tid = @index(Global, Linear)
@inbounds r_0 = input_pts[tid, 1]^2 + input_pts[tid, 2]^2
# this method is only valid for points within the unit circle
if r_0 == 0 || r_0 > 1
@inbounds output_pts[tid,1] = NaN
@inbounds output_pts[tid,2] = NaN
else
@inbounds output_pts[tid,1] = sigma * input_pts[tid,1] *
sqrt(-2 * log(r_0) / r_0) + mu
@inbounds output_pts[tid,2] = sigma * input_pts[tid, 2] *
sqrt(-2 * log(r_0) / r_0) + mu
end
end
@kernel function polar_muller_replacement!(input_pts, output_pts, sigma, mu)
tid = @index(Global, Linear)
@inbounds r_0 = input_pts[tid, 1]^2 + input_pts[tid, 2]^2
while r_0 > 1 || r_0 == 0
p1 = rand()*2-1
p2 = rand()*2-1
r_0 = p1^2 + p2^2
end
@inbounds output_pts[tid,1] = sigma * input_pts[tid,1] *
sqrt(-2 * log(r_0) / r_0) + mu
@inbounds output_pts[tid,2] = sigma * input_pts[tid, 2] *
sqrt(-2 * log(r_0) / r_0) + mu
end
function polar_box_muller!(input_pts, output_pts, sigma, mu;
numthreads = 256, numcores = 4,
f = polar_muller_noreplacement!)
if isa(input_pts, Array)
kernel! = f(CPU(), numcores)
else
kernel! = f(CUDADevice(), numthreads)
end
kernel!(input_pts, output_pts, sigma, mu, ndrange=size(input_pts)[1])
end
@kernel function cartesian_kernel!(input_pts, output_pts, sigma, mu)
tid = @index(Global, Linear)
@inbounds r = sqrt(-2 * log(input_pts[tid,1]))
@inbounds theta = 2 * pi * input_pts[tid, 2]
@inbounds output_pts[tid,1] = sigma * r * cos(theta) + mu
@inbounds output_pts[tid,2] = sigma * r * sin(theta) + mu
end
function cartesian_box_muller!(input_pts, output_pts, sigma, mu;
numthreads = 256, numcores = 4)
if isa(input_pts, Array)
kernel! = cartesian_kernel!(CPU(), numcores)
else
kernel! = cartesian_kernel!(CUDADevice(), numthreads)
end
kernel!(input_pts, output_pts, sigma, mu, ndrange=size(input_pts)[1])
end
function main()
input_pts = create_rand_dist(4096^2,[0,1])
output_pts = create_rand_dist(4096^2,[0,1])
wait(cartesian_box_muller!(input_pts, output_pts, 1, 0))
@time wait(cartesian_box_muller!(input_pts, output_pts, 1, 0))
wait(polar_box_muller!(input_pts, output_pts, 1, 0))
@time wait(polar_box_muller!(input_pts, output_pts, 1, 0))
if has_cuda_gpu()
input_pts = create_rand_dist(4096^2,[0,1], AT = CuArray)
output_pts = create_rand_dist(4096^2,[0,1], AT = CuArray)
wait(cartesian_box_muller!(input_pts, output_pts, 1, 0))
CUDA.@time wait(cartesian_box_muller!(input_pts, output_pts, 1, 0))
wait(polar_box_muller!(input_pts, output_pts, 1, 0))
CUDA.@time wait(polar_box_muller!(input_pts, output_pts, 1, 0))
end
end
main()
License
Code Examples
The code examples are licensed under the MIT license (found in LICENSE.md).
Text
The text of this chapter was written by James Schloss and is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License.
![]()